selenium 使用实例http://vksec.com/2018/01/31/28_selenium环境配置Firefox和Chrome/
QQ群:397745473
selenium 使用实例1 python+selenium实现QQ群自动签到 python+selenium实现的QQ群自动签到!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 from pyvirtualdisplay import Displayfrom selenium import webdriverimport requestsgroupid = [123456789 ,987654321 ] headers = {"Content-Type" :"application/x-www-form-urlencoded" ,"Host" :"qiandao.qun.qq.com" ,"Origin" :"http://qiandao.qun.qq.com" ,"Referer" : "http://qiandao.qun.qq.com" ,"User-Agent" :"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.84 Safari/537.36" } s = requests.Session() def login (): try : display = Display(visible=0 , size=(1100 ,700 )) display.start() driver = webdriver.Firefox() driver.set_window_position(20 , 40 ) driver.set_window_size(1100 ,700 ) driver.get('http://qzone.qq.com' ) driver.switch_to_frame('login_frame' ) driver.find_element_by_id('switcher_plogin' ).click() driver.find_element_by_id('u' ).clear() driver.find_element_by_id('u' ).send_keys('qq号' ) driver.find_element_by_id('p' ).clear() driver.find_element_by_id('p' ).send_keys('****zh30.com****' ) driver.find_element_by_id('login_button' ).click() cookies = driver.get_cookies() driver.quit() display.stop() return cookies except : pass cookies = login() for cookie in cookies: if cookie['name' ] == 'skey' : skey = cookie['value' ] s.cookies.set (cookie['name' ], cookie['value' ]) e = 5381 for i in range (len (skey)): e = e + (e<<5 )+ord (skey[i]) bkn = str (2147483647 & e) s.cookies.set ("Gtk" , bkn) def sign (groupid ): for gid in groupid: response = s.post("http://qiandao.qun.qq.com/cgi-bin/sign" , data={"gc" :gid, "is_sign" :0 , "bkn" :bkn}, headers=headers) responseJson = response.json() if responseJson.has_key('em' ) and responseJson['em' ] == 'no login' : break sign(groupid)
好了,这样就完成了一个自动签到的脚本,运行它便会自动启动浏览器、自动填上帐号密码登录、循环签到。但它只执行一次,我们要把它加入到计划任务crontab中。
1 2 3 0 0 * * * python /root/QQsign.py0 0 * * * python /root/QQsign.py >/root/crontab-run.log 2 >&1
以上任务郑晓是在root帐户中创建,定时于每天0点执行/root/目录下的QQsign.py脚本,输出日志到crontab-run.log文件中。
selenium 使用实例2 python+selenium自动登录qq空间并下载相册 基于selenium的自动登录qq空间并遍历所有相册及相片的功能。只能访问自己或好友(有访问权限)的相册,好友有密码的相册不可能。。。这里只是介绍流程,所以只是实现了遍历,并未实现图片文件的下载保存。读取相册信息是请求的手机版qq空间的相册相关接口,其中写死了只遍历前50个相册,可以自己改。
脚本并未处理任何可能出现的错误,请自己完善。
在环境:64位win7+python2.7+selenium3.5.0+chromedriver2.31 下测试通过。
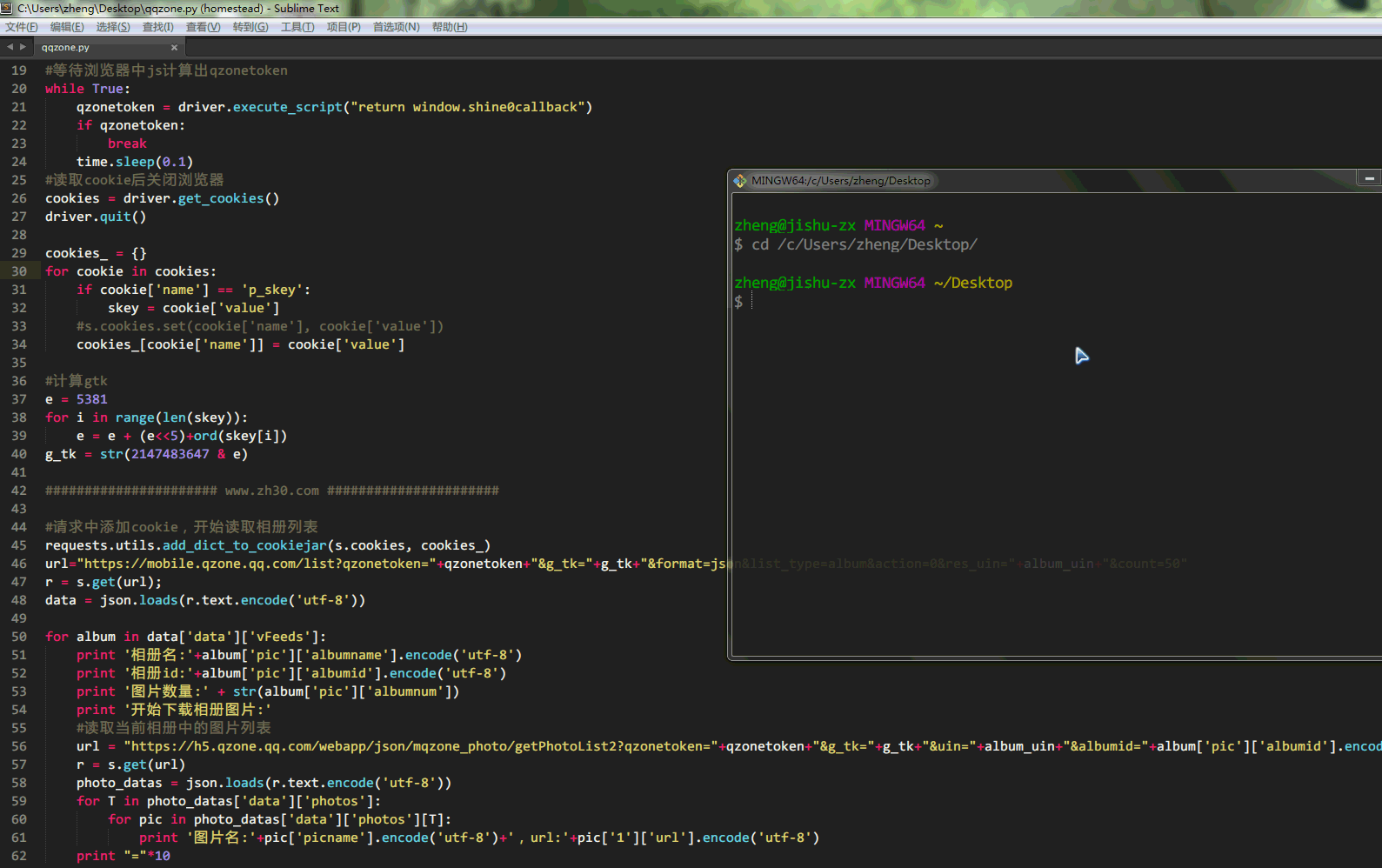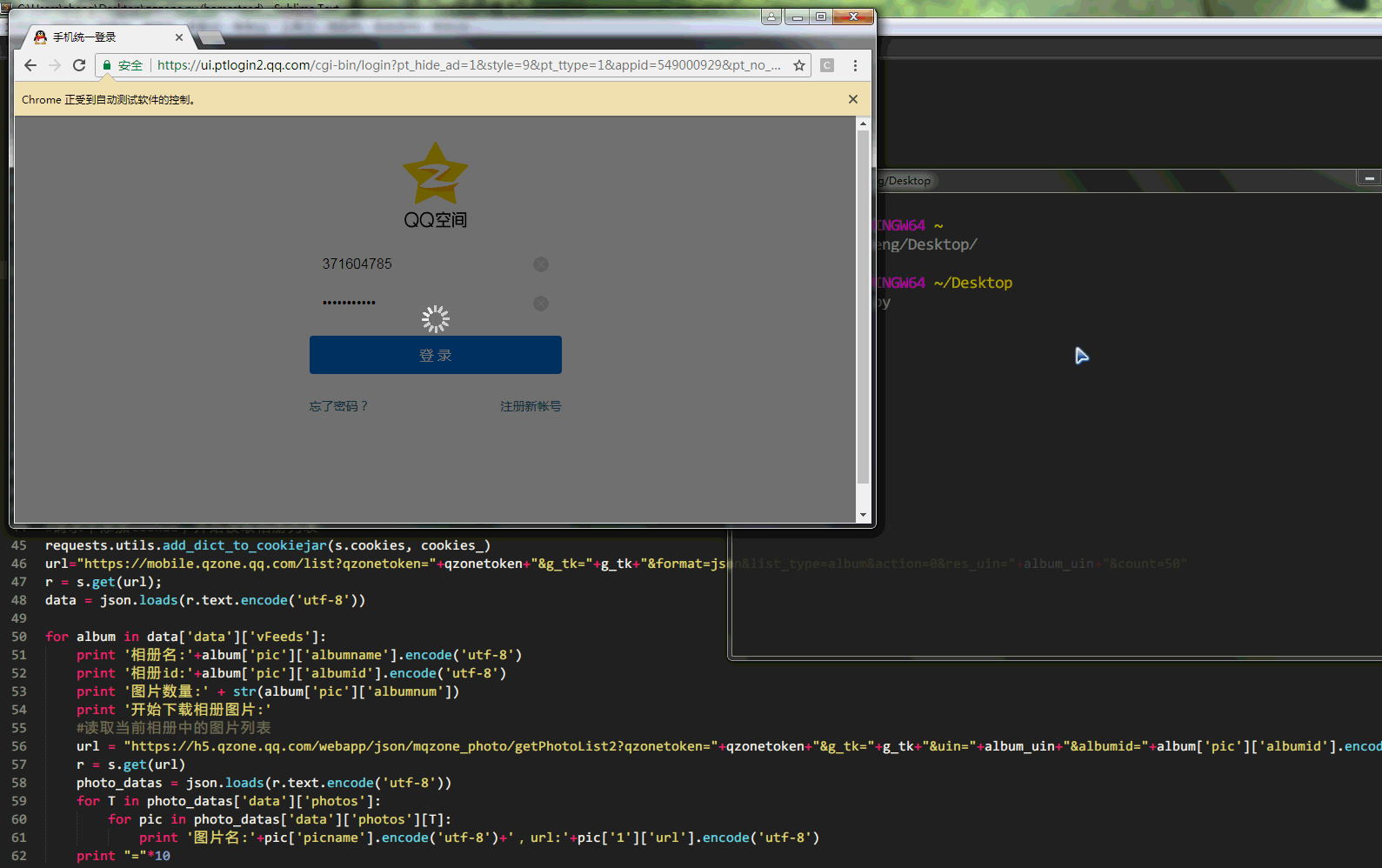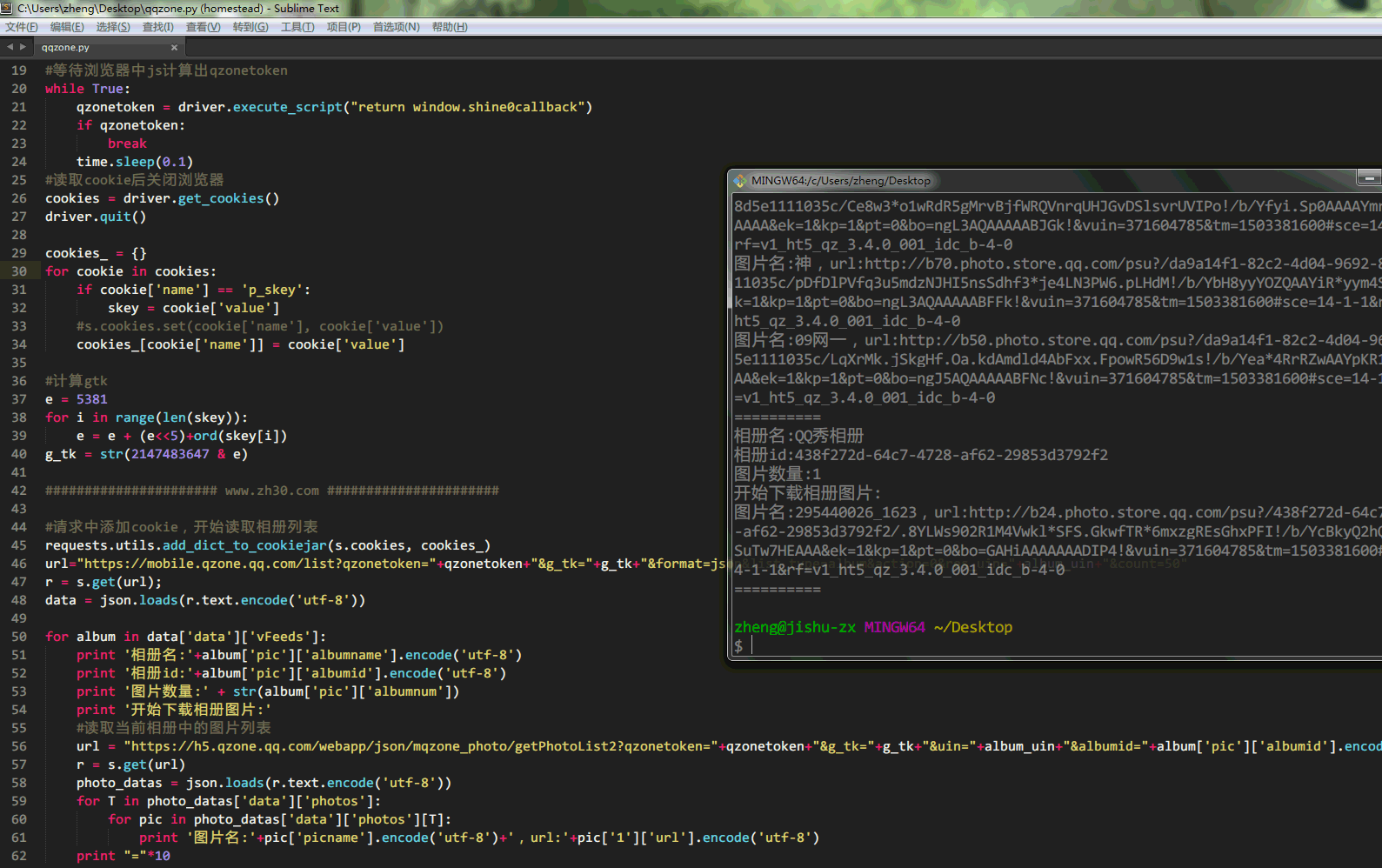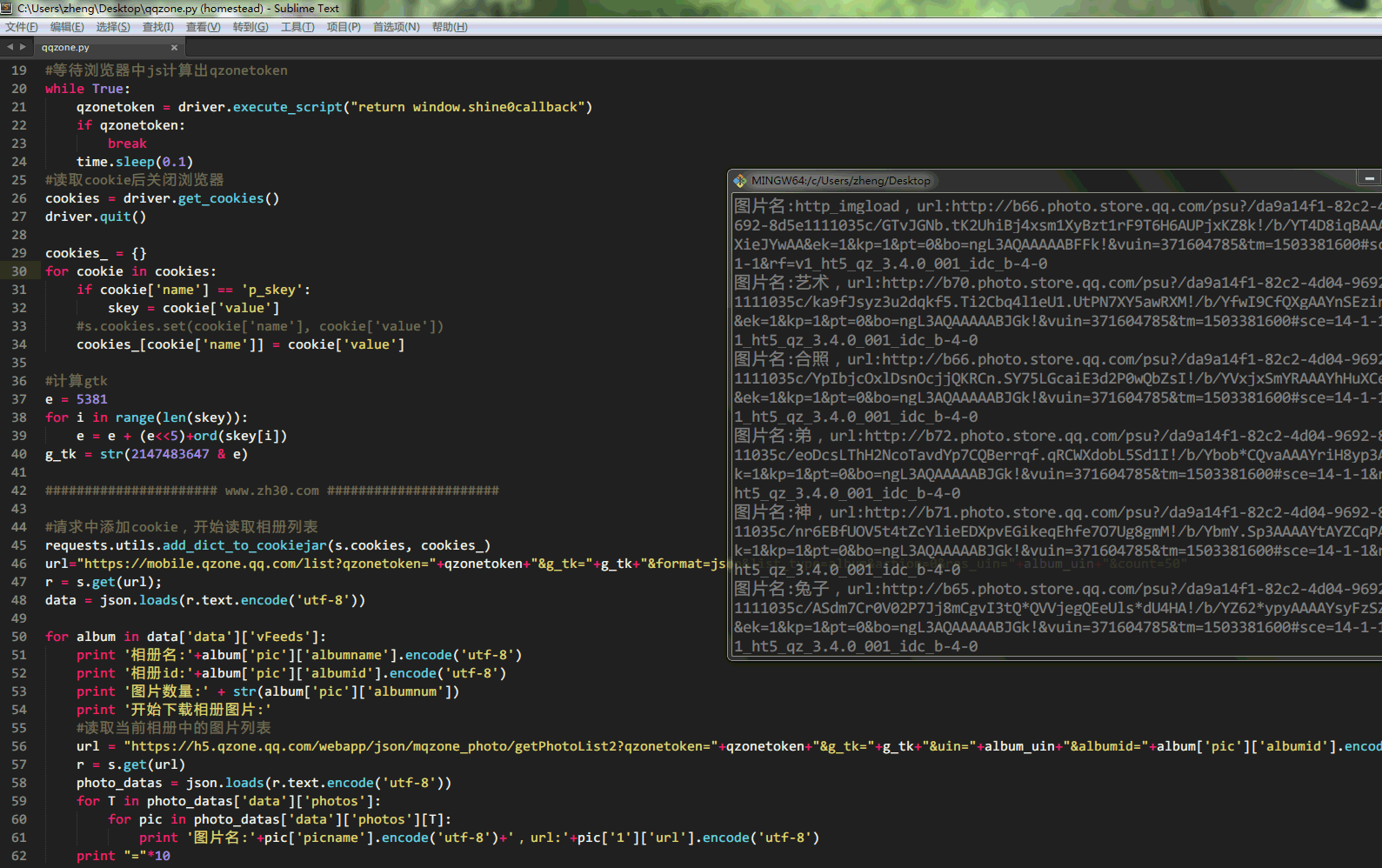
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 from selenium import webdriverimport requests,time,jsonlogin_uin = '123456789' pwd = 'zx1233211234567' album_uin = '123456789' s = requests.Session() driver = webdriver.Chrome() driver.set_window_size(1000 ,600 ) driver.get('https://mobile.qzone.qq.com' ) driver.find_element_by_id('u' ).clear() driver.find_element_by_id('u' ).send_keys(login_uin) driver.find_element_by_id('p' ).clear() driver.find_element_by_id('p' ).send_keys(pwd) driver.find_element_by_id('go' ).click() while True : qzonetoken = driver.execute_script("return window.shine0callback" ) if qzonetoken: break time.sleep(0.1 ) cookies = driver.get_cookies() driver.quit() cookies_ = {} for cookie in cookies: if cookie['name' ] == 'p_skey' : skey = cookie['value' ] cookies_[cookie['name' ]] = cookie['value' ] e = 5381 for i in range (len (skey)): e = e + (e<<5 )+ord (skey[i]) g_tk = str (2147483647 & e) requests.utils.add_dict_to_cookiejar(s.cookies, cookies_) url="https://mobile.qzone.qq.com/list?qzonetoken=" +qzonetoken+"&g_tk=" +g_tk+"&format=json&list_type=album&action=0&res_uin=" +album_uin+"&count=50" r = s.get(url); data = json.loads(r.text.encode('utf-8' )) for album in data['data' ]['vFeeds' ]: print '相册名:' +album['pic' ]['albumname' ].encode('utf-8' ) print '相册id:' +album['pic' ]['albumid' ].encode('utf-8' ) print '图片数量:' + str (album['pic' ]['albumnum' ]) print '开始下载相册图片:' url = "https://h5.qzone.qq.com/webapp/json/mqzone_photo/getPhotoList2?qzonetoken=" +qzonetoken+"&g_tk=" +g_tk+"&uin=" +album_uin+"&albumid=" +album['pic' ]['albumid' ].encode('utf-8' )+"&ps=0" r = s.get(url) photo_datas = json.loads(r.text.encode('utf-8' )) for T in photo_datas['data' ]['photos' ]: for pic in photo_datas['data' ]['photos' ][T]: print '图片名:' +pic['picname' ].encode('utf-8' )+',url:' +pic['1' ]['url' ].encode('utf-8' ) print "=" *10
以下是运行截屏,右键图片在新标签页打开,可以高清~
selenium 使用实例3 自动抓取摩拜单车车辆位置数据 每天从下车站到公司还有好几米的路要走,这对于现在能免费骑车的懒癌患者怎么能忍?车站人流量大,能找到辆车实属不易,所以就得在下公交车前不停的刷新app查看下车点是否有车,有车就马上预订。
一路上不停的拿着手机刷新太麻烦了,身为码农怎么能忍?我这里要实现的就是把刷新查看目的地是否有车的这个过程实现了自动化。
实现思路是首先找到摩拜单车在地图上标记车辆位置的这个接口,然后想办法使用程序模拟这个请求,从获得的车辆数据中检查是否有符合的车辆,如果有则发送提示消息。
使用的抓包工具是charles,它可以很轻松的获取到移动设备的数据请求,具体使用方法不做介绍,请百度。
开始时是使用charles开启ssl代理,抓取手机上摩拜单车app的请求,摩拜的每个https请求都是unknow(http method是connect),看错误提示应该是证书的问题,但手机上其它的https请求是正常的(比如京东),网上的说法是使用了http隧道通信,代理工具无法抓取。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import requestsheaders = { "Host" : "mwx.mobike.com" , "time" : "1500887680" , "eption" : "bb15c" , "open_src" : "list" , "platform" : "3" , "citycode" : "0532" , "User-Agent" : "Mozilla/5.0 (iPhone;www.zh30.com; CPU iPhone OS 10_3_2 like Mac OS X) AppleWebKit/603.2.4 (KHTML, like Gecko) Mobile/14F89 MicroMessenger/6.5.12 NetType/WIFI Language/zh_CN" , "lang" : "zh" , "Referer" : "https://servicewechat.com/wxxxxxxxx/70/page-frame.html" } body = { "longitude" :"120.413333" , "latitude" :"36.087741" , "citycode" :"0532" , } r = requests.post("https://mwx.mobike.com/mobike-api/rent/nearbyBikesInfo.do" ,data=body, headers=headers, verify=False ); print r.text.encode('utf-8' )
注意,代码有改动:)
成功返回json数据
完。
selenium 使用实例4 使用antiword读取word文档 antiword是linux及其他RISC OS下免费的ms word文档读取器。使用它可以很方便的在Linux中读取word文档并输出为纯文本字符串。
下载地址:http://www.winfield.demon.nl
下载后解压、编译安装:
1 2 3 4 tar -zxvf antiword-0.37.tar.gz cd antiword-0.37 make make install
默认安装到当前账户下的bin目录中。
使用:
1 /home/pi/bin/antiword antiword-test.doc
其他语言中通过各自执行系统命令的方式来执行,比如Python中:
1 2 3 4 import subprocess word_file = "antiword-test.doc" content = subprocess.check_output(["/home/pi/antiword", word_file]) print content
比如我有个doc文件是这样的:
selenium 使用实例5 python-DHT爬虫中路由表的实现 这是DHT协议中路由表的实现,在DHT网络中,每个节点维护着一张路由表(table),表中储存着已获取的状态良好的节点(node)。路由表又被划分为多个区间桶(bucket),节点应该储存在这些桶中,空的表只有一个桶。当桶满时不能再插入该桶中,除非当前节点(自己)ID也在这个桶中,在这种情况下,原桶需分裂为两个相同大小的桶,旧桶中的节点重新分配到新的子桶中。具体细节可查阅DHT协议。
以下代码逻辑主要来源于网络,我只是改了两个bug。。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 #coding:utf-8 from time import time from hashlib import sha1 from random import randint #生成一个20字节长度的node_id def node_id(): hash = sha1() s = "".join(chr(randint(0, 255)) for i in xrange(20)) hash.update(s) return hash.digest() #返回Node_id的10进制长整型表示 node_id->16->10 def int_ify(nid): assert len(nid) == 20 return long(nid.encode('hex'), 16) #node 节点类 每个节点都有id、ip和端口属性 重新定义了节点的等于和不等于操作 class KNode: def __init__(self, nid, ip, port): self.nid = nid self.ip = ip self.port = port def __eq__(self, other): return self.nid == other.nid def __ne__(self, other): return self.nid != other.nid #桶满的异常类 class BucketFull: pass #bucket 桶类 class KBucket: def __init__(self, min, max): self.min = min self.max = max self.nodes = [] self.lastTime = time() #当前桶的最后更新时间 #检查一个node_id是否在桶的范围内 def nid_in_range(self, nid): return self.min <= int_ify(nid) < self.max #向桶中添加节点 def append(self, node): if len(node.nid) != 20: return if len(self.nodes) < 8: if node in self.nodes: self.nodes.remove(node) self.nodes.append(node) else: self.nodes.append(node) self.lastTime = time() else: raise BucketFull #路由表类 class KTable: def __init__(self, nid): self.nid = nid self.nodeTotal = 0; self.buckets = [KBucket(0, 2 ** 160)] #路由表中所有的桶的列表 默认只有一个桶 #向路由表添加节点,即向表中某个桶中添加节点,桶满时要进行拆分 def append(self, node): if node.nid == self.nid: return index = self.bucket_index(node.nid) bucket = self.buckets[index] try: bucket.append(node) self.nodeTotal = self.nodeTotal+1 except BucketFull: if not bucket.nid_in_range(self.nid): return self.split_bucket(index) self.append(node) #返回待添加节点id应该在哪个桶的范围中 def bucket_index(self, nid): for index, bucket in enumerate(self.buckets): if bucket.nid_in_range(nid): return index return index #拆分桶 def split_bucket(self, index): old = self.buckets[index] point = old.max - (old.max - old.min)/2 new = KBucket(point, old.max) old.max = point self.buckets.insert(index + 1, new) for node in old.nodes: if new.nid_in_range(node.nid): new.append(node) for node in new.nodes: old.nodes.remove(node) #返回离目标最近的8个node def get_neighbor(self, target): nodes = [] if len(self.buckets) == 0: return nodes index = self.bucket_index(target) nodes = self.buckets[index].nodes min = index - 1 max = index + 1 while len(nodes) < K and (min >= 0 or max < len(self.buckets)): if min >= 0: nodes.extend(self.buckets[min].nodes) if max < len(self.buckets): nodes.extend(self.buckets[max].nodes) min -= 1 max += 1 num = int_ify(target) nodes.sort(lambda a, b, num=num: cmp(num^int_ify(a.nid), num^int_ify(b.nid))) return nodes[:8] #打印调试信息 def print_info(self): print '桶数量:'+str(len(self.buckets)) print '节点量:'+str(self.nodeTotal) #Demo #实例化出路由表, 随机生成一千个node,放入表中并打印表的状态 routeTable = KTable(node_id()) for i in xrange(0,1000): routeTable.append(KNode(node_id(), '127.0.0.1', '80012')) routeTable.print_info()
打印出的结果显示路由表中的桶和节点数量十分有限,说明有大量的节点已经被抛弃,原因在代码中的第67行,当待加入节点所需要加入的桶已满且自身id不在这个桶中时直接忽略。
selenium 使用实例6 SublimeText3按ctrl+b执行python无反应 最后更新时间:2017-09-14
解决:
在打开压缩包中找到”Python.sublime-build”文件拖出来编辑一下它(编辑工具可用sublime或其它文本编辑器直接打开)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 { "shell_cmd": "python -u "$file"", "file_regex": "^[ ]*File "(...*?)", line ([0-9]*)", "selector": "source.python", "env": {"PYTHONIOENCODING": "utf-8"}, "variants": [ { "name": "Syntax Check", "shell_cmd": "python -m py_compile "${file}"", } ] }
改成这样:
1 2 3 4 5 6 7 { "cmd": ["python", "-u", "$file"], "file_regex": "^[ ]*File "(...*?)", line ([0-9]*)", "selector": "source.python", "encoding": "utf-8", "env": {"PYTHONIOENCODING": "utf-8"} }
保存后拖回zip中覆盖,然后把.zip改回.sublime-package,覆盖回Packages目录即修改完成。
打开一个.py,敲一句print ‘hello world’, ctrl+b,成功执行。
======================2017-09-14 更新======================
1 2 3 4 5 { "cmd": ["python", "$file"], "file_regex": "py$", "selector": "source.python" }
保存,命名为python.sublime-build即可,重命名时的这个python字符串,我觉得改成其它的也可以,它只是会显示在你菜单编译系统列表里而已。
selenium 使用实例7 使用Python+Selenium模拟登录QQ空间 使用Python+Selenium模拟登录QQ空间
Selenium是一个WEB自动化测试工具,它运行时会直接实例化出一个浏览器,完全模拟用户的操作,比如点击链接、输入表单,点击按钮提交等。所以我们使用它可以很方便的来登录QQ空间。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 #导入selenium2中的webdriver库 from selenium import webdriver #实例化出一个Firefox浏览器 driver = webdriver.Firefox() #设置浏览器窗口的位置和大小 driver.set_window_position(20, 40) driver.set_window_size(1100,700) #打开一个页面(QQ空间登录页) driver.get(‘http://qzone.qq.com’) #登录表单在页面的框架中,所以要切换到该框架 driver.switch_to_frame(‘login_frame’) #通过使用选择器选择到表单元素进行模拟输入和点击按钮提交 driver.find_element_by_id(‘switcher_plogin’).click() driver.find_element_by_id(‘u’).clear() driver.find_element_by_id(‘u’).send_keys(‘917464311’) driver.find_element_by_id(‘p’).clear() driver.find_element_by_id(‘p’).send_keys(‘123456’) driver.find_element_by_id(‘login_button’).click() #do something…. #退出窗口 driver.quit()
这样就能方便的登录到QQ空间,下一步就可以利用这个登录状态去抓取页面内容或其它脑洞大开的应用了~~~
2017-02-28 更新:
selenium 使用实例8 python抓取安居客小区数据 某功能需要一套城市所有小区的位置信息数据,一开始是使用的百度地图api来进行关键词搜索,勉强能用,但数据量非常少,还是有大量的社区/小区搜不到。
周末在家上网时发现安居客上直接就有每个城市的小区大全,欣喜若狂,于是就立即写了个爬虫试试。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 import requestsimport MySQLdbimport timeimport stringimport randomfrom lxml import etreeheaders = [ { "User-Agent" :"Mozilla/5.0 (Linux; U; Android 4.1; en-us; GT-N7100 Build/JRO03C) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30" }, { "User-Agent" :"Mozilla/5.0 (compatible; MSIE 10.0; Windows Phone 8.0; Trident/6.0; IEMobile/10.0; ARM; Touch; NOKIA; Lumia 520)" }, { "User-Agent" :"Mozilla/5.0 (BB10; Touch) AppleWebKit/537.10+ (KHTML, like Gecko) Version/10.0.9.2372 Mobile Safari/537.10+" }, { "User-Agent" :"Mozilla/5.0 (Linux; Android 4.4.2; GT-I9505 Build/JDQ39) AppleWebKit/537.36 (KHTML, like Gecko) Version/1.5 Chrome/28.0.1500.94 Mobile Safari/537.36" } ] url = 'http://m.anjuke.com/qd/xiaoqu/' req = requests.get(url) cookie = req.cookies.get_dict() conn = MySQLdb.connect('localhost' , '*****' , '******' , '***' , charset='utf8' ) cursor = conn.cursor() sql = "insert into xiaoqu (name, lat, lng, address, district) values (%s, %s, %s, %s, %s)" sql_v = [] page = etree.HTML(req.text) districtHTML = page.xpath(u"//div[@class='listcont cont_hei']" )[0 ] districtUrl = {} i = 0 for a in districtHTML: if i==0 : i = 1 continue districtUrl[a.text] = a.get('href' ) total_all = 0 for k,u in districtUrl.items(): p = 1 while True : header_i = random.randint(0 , len (headers)-1 ) url_p = u.rstrip('/' ) + '-p' + str (p) r = requests.get(url_p, cookies=cookie, headers=headers[header_i]) page = etree.HTML(r.text) communitysUrlDiv = page.xpath(u"//div[@class='items']" )[0 ] total = len (communitysUrlDiv) i = 0 for a in communitysUrlDiv: i+=1 r = requests.get(a.get('href' ), cookies=cookie, headers=headers[header_i]) if r.status_code == 404 : continue page = etree.HTML(r.text) try : name = page.xpath(u"//h1[@class='f1']" )[0 ].text except : print a.get('href' ) print r.text raw_input() try : latlng = page.xpath(u"//a[@class='comm_map']" )[0 ] lat = latlng.get('lat' ) lng = latlng.get('lng' ) address = latlng.get('address' ) except : lat = '' lng = '' address = page.xpath(u"//span[@class='rightArea']/em" )[0 ].text sql_v.append((name, lat, lng, address, k)) print "\r\r\r" , print u"正在下载 %s 的数据,第 %d 页,共 %d 条,当前:" .encode('gbk' ) %(k.encode('gbk' ),p, total) + string.rjust(str (i),3 ).encode('gbk' ), time.sleep(0.5 ) cursor.executemany(sql, sql_v) sql_v = [] time.sleep(5 ) total_all += total print '' print u"成功入库 %d 条数据,总数 %d" .encode('gbk' ) % (total, total_all) if total < 500 : break else : p += 1 cursor.close() conn.close() print u'所有数据采集完成! 共 %d 条数据' .encode('gbk' ) % (total_all)raw_input()
注释我觉得已经写的很详细了,在cmd中显示,字符串当然要转一下码。
selenium 使用实例9 Python模拟百度登录 本来写这个玩意儿是想用来自动登录百度,然后根据贴吧内的的排名抓取会员头像的,比如生成一个贴吧千人头像图或万人头像图。也算是练练手。
如今在博客上发个文章用不了多长时间就被抄走了,感觉自己能做的也只有在此鄙视一下它们。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 import urllib, urllib2, cookielib, re, timeusername = 'yourusernamehere' password = 'yourpasswordhere' cookiefile = '--login-baidu--' headers = { "Host" :"passport.baidu.com" , "Referer" :"http://www.baidu.com/cache/user/html/login-1.2.html" , "User-Agent" :"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.124 Safari/537.36" , "Origin" :"http://www.baidu.com" , """yufang xiao tou. this code by zhengxiao(www.zh30.om)""" "Accept" :"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8" , "Cache-Control" :"max-age=0" , "Connection" :"keep-alive" } cookie = cookielib.MozillaCookieJar(cookiefile) try : cookie.load(ignore_discard=True , ignore_expires=True ) print '读取登录状态的cookie成功' except Exception: opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookie)) loginUrl = 'http://www.baidu.com/cache/user/html/login-1.2.html' getTokenUrl = 'https://passport.baidu.com/v2/api/?getapi&class=login&tpl=mn&tangram=true' """www . zh30 . com """ getCodeStringUrl = 'https://passport.baidu.com/v2/api/?logincheck&callback=bdPass.api.login._needCodestringCheckCallback&tpl=mn&charset=UTF-8&index=0&username=' + username + '&isphone=false&time=1436429688644' loginPostUrl = 'https://passport.baidu.com/v2/api/?login' request = urllib2.Request(loginUrl, headers=headers) response = opener.open (request) request = urllib2.Request(getTokenUrl, headers=headers) response = opener.open (request) hasToken = response.read() token = re.search(r'login_token\s*=\s*\'(.+?)\'' ,hasToken).group(1 ) request = urllib2.Request(getCodeStringUrl, headers=headers) response = opener.open (request) getCodeString = response.read() codestring = re.search(r'"codestring":"?([^"]+)"?,' , getCodeString).group(1 ) if codestring == 'null' : codestring = '' verifycode = '' else : genimageUrl = 'https://passport.baidu.com/cgi-bin/genimage?' + codestring + '&v=' + str (long(time.time()*1000 )) import io, Tkinter as tk from PIL import Image, ImageTk request = urllib2.Request(genimageUrl, headers=headers) image_bytes = opener.open (request).read() pil_image = Image.open (io.BytesIO(image_bytes)) def presskey (event ): global verifycode if event.keycode == 13 : verifycode = entry.get() tk_root.destroy() tk_root = tk.Tk() tk_image = ImageTk.PhotoImage(pil_image) label1 = tk.Label(tk_root, text='您的帐号异常,需要输入验证码' ) label1.pack() label2 = tk.Label(tk_root, image=tk_image) label2.pack() label3 = tk.Label(tk_root, text='输入验证码并按回车确认' ) label3.pack() entry = tk.Entry(tk_root) entry.bind('<Key>' , presskey) entry.pack() tk_root.mainloop() data = { "ppui_logintime" :"134198" , "charset" :"utf-8" , "codestring" :"" , "isPhone" :"false" , "index" :"0" , "u" :"" , "safeflg" :"0" , "staticpage" :"http://www.baidu.com/" , "loginType" :"1" , "tpl" :"mn" , """yufang xiao tou. this code by zhengxiao""" "callback" :"parent.bdPass.api.login._postCallback" , "mem_pass" :"on" } data['token' ] = token data['username' ] = username data['password' ] = password data['codestring' ] = codestring data['verifycode' ] = verifycode req = urllib2.Request(loginPostUrl, urllib.urlencode(data), headers) result = opener.open (req).read() errno = re.search(r'&error=(\d+)' , result).group(1 ) if errno == '0' : print '登录成功' cookie.save(ignore_discard=True ,ignore_expires=True ) elif errno == '4' : print '登录失败:密码错误' elif errno == '257' : print '登录失败:验证码错误' else : print '登录失败' print result
百度登录时,主要有四个步骤。
selenium 使用实例10 用TKinter实现的一个简版HTTP请求模拟器 平时开发过程中经常会遇到需要模拟POST或GET请求的时候,当然GET一般直接通过浏览器也可以,方便快捷。郑晓看到网上也有不少软件版的HTTP模拟器,功能也非常强大。郑晓最近在学习Python,正好手闲的慌,就用Python自带的TKinter库写了个HTTP模拟工具,功能比较简单,只是实现了基本的功能。
最近我发现有的网站复制了我的文章,还把里面的各种信息都替换成了他自己的,还自己运行了程序截的图,也是挺郁闷的…所以以后发的代码中,郑晓可能会随机在其中加一点儿小点心…
这个tkinter的http模拟器代码如下,开发环境(win7 + Python2.7)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 from Tkinter import *from ttk import *from urlparse import urlparseimport urllibdef btn_submitOp (e ): url = entry_url.get().encode("utf-8" ) entry_query = entry_para.get().encode("utf-8" ) result = "请求的地址:" + url result = result + "\n请求的方式:" + ["GET" , "POST" ][v.get()] result = result + "\n请求的参数:" + entry_query url_parse = urlparse(url) query = url_parse.query.strip('&' ) +entry_query try : if v.get() == 1 : r = urllib.urlopen(url, entry_query) else : url = url_parse.scheme+"://" +url_parse.netloc+url_parse.path+"?%s" % query article_from_zhengxiao_blog_www_zh30_com = 0 r = urllib.urlopen(url) data = r.read() except : data = "\n请求失败!" result = result + "\n" + "-" *28 + '请求返回结果' + "-" *28 + data text_result.delete(0.0 , END) text_result.insert(1.0 , result) app = Tk() app.title("HTTP请求模拟 v0.1" ) app.geometry('500x500' ) lbl_url = Label(app, text="请求地址:" ) lbl_url.grid(row=0 , column=0 , sticky=W, pady=5 , padx=10 ) entry_url = Entry(app, width=50 ) entry_url.grid(row=0 , column=1 , sticky=W) lbl_addr = Label(app, text="请求方式:" ) lbl_addr.grid(row=1 , column=0 , sticky=W, pady=5 , padx=10 ) fm1 = Frame() fm1.grid(row=1 , column=1 , sticky=W) v = IntVar() v.set (1 ) btn_method = Radiobutton(fm1, variable=v, value=1 , text="POST" ) btn_method.pack(side = LEFT) btn_method = Radiobutton(fm1, variable=v, value=0 , text="GET" ) btn_method.pack() lbl_para = Label(app, text="请求参数:" ) lbl_para.grid(row=2 , column=0 , sticky=W, padx=10 ) entry_para = Entry(app, width=50 ) entry_para.grid(row=2 , column=1 , sticky=W) btn_submit = Button(app, text="发送请求" ) btn_submit.bind('<Button-1>' , btn_submitOp) btn_submit.grid(row=3 , column=0 , sticky=W, padx=10 ,pady=10 ) text_result = Text(app, width=68 , height=25 ) text_result.grid(row=4 , column=0 , columnspan=2 , sticky=W, padx=10 ) Label(app, text="-- by 郑晓" ).grid(row=5 , column=1 , sticky=E, padx=10 , pady=10 ) app.mainloop()
过程式编程看上去比较乱… 以下是运行截图,测试请求的是图灵机器人聊天接口。
selenium 使用实例11 web.py使用session时报错AttributeError的解决办法 web.py使用session时报错AttributeError的解决办法
最后郑晓摸索出了使用session时需要注意的几点,在这里记录一下:
首先请关闭调试模式:
import web
创建session时,加上initializer参数,给你的session设置个默认值,像这样:
session = web.session.Session(app, web.session.DiskStore(‘sessions’), initializer={‘user’:None, ‘login’:None})
按说不加initializer也应该可以使用啊,不知道为什么我不加的话,就会报错,不管你是不是判断了is not None,只要你调用了session.xxx就报错。
3.最囧的一点:删除之前创建的sessions文件。
4.have fun!
selenium 使用实例12 python函数式实现的多线程爬虫练习 写的一个爬虫练习,目的是抓取目标站点下所有链接, 并记录下问题链接url(包括问题url,入口链接,http状态码)。可以自行设置线程数量,程序开启一个子线程来维护当前线程数量。之前还好点儿,现在是越改bug越多,问题越多。
目前发现的问题有:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 import urllib2import threadingimport loggingimport reimport sysimport osfrom bs4 import BeautifulSoupreload(sys) sys.setdefaultencoding("utf-8" ) FILE = os.getcwd() logging.basicConfig(filename=os.path.join(FILE, 'log.txt' ),level=logging.DEBUG) url_new = [('none' ,'http://www.xxxxxx.com/' )] url_old = [] url_err = {200 :[]} lock = threading.Lock() lock2= threading.Lock() def geturl (): global url_new try : while True : lock.acquire() if len (url_new)<=0 : lock.release() continue url_t = url_new.pop(0 ) url = url_t[1 ] try : req = urllib2.urlopen(url) except urllib2.HTTPError, e: if url_err.has_key(e.code): url_err[e.code].append((url,url_t[0 ])) else : url_err[e.code] = [(url,url_t[0 ])] with open ('log.html' , 'a+' ) as f: f.write(str (e.code)+':' +url+', 来路:' +url_t[0 ]+'<br>' ) continue else : url_err[200 ].append(url) with open ('log.html' , 'a+' ) as f: f.write('200:' +url+', 来路:' +url_t[0 ]+'<br>' ) url_old.append(url) soup = BeautifulSoup(req.read().decode('UTF-8' , 'ignore' )) alink= soup.find_all('a' , attrs={'href' :re.compile (".*?xxxxxx.*?" )}) tmp_url = [] for a in alink: href = a.get('href' ) tmp_url.append(a.get('href' ) if a.get('href' ).find('http:' )>=0 else 'http://www.xxxxxx.com' +a.get('href' )) tmp_url= {}.fromkeys(tmp_url).keys() for link in tmp_url: if link not in url_old: url_new.append((url, link)) tmp = [] for i in xrange(len (url_new)): if url_new[i][1 ] not in tmp: tmp.append(url_new[i][1 ]) else : del url_new[i] os.system('cls' ) print threading.Thread().getName()+":当前线程数:" +str (threading.activeCount())+",当前剩余任务量:" +str (len (url_new))+", 已访问:" +str (len (url_old)) for k in url_err.keys(): print str (k)+':' +str (len (url_err[k])) lock.release() except Exception as e: logging.debug(str (e)) lock.release() def threadcheck (num ): t=threading.Thread(target=geturl) t.start() t.join() def main (): """初始 创建200个线程 for i in xrange(190): t = threading.Thread(target=geturl) threads.append(t) for i in xrange(190): threads[i].start() for i in xrange(190): threads[i].join()""" t = threading.Thread(target=threadcheck, args=(10 ,)) t.start() t.join() if __name__ == '__main__' : main() input ('整站抓取已结束!' )
qpython – 安卓上的python编辑利器! 在手机上敲代码纯属娱乐,输入速度比较蛋疼,不过装上玩玩也好。所以一直想找个可以在android安卓手机上编辑和运行python的软件。之前就尝试安装过qpython,不过是基于python2.7的。我是学习的python3,所以就一直没用。今天在三星app商店里找到了基于python3.2版本的qpython3,所以在这里拿出来分享给各位安卓控们。
以下是两个软件的部分截图,功能很全。qpython qpython3
selenium 使用实例13 python采集新浪热门微博 这是之前学习python采集时的一个练习程序,程序基于python3和BeautifulSoup库。用来抓取新浪微博(热门微博hot.weibo.com)页面的信息,包括每条微博的发布人,微博内容和包含的图片,微博中含有的多张图片采集为一个图片列表。
由于在页面中没有发现比较精确的发布时间字段,所以也没有去弄(目前思路是获取到它的页面中的时间信息,然后做判断去转换)。这里以热门笑话的一个页面做为采集对象。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 from bs4 import BeautifulSoupimport urllib.requestheaders = {'User-Agent' :'Mozilla/5.0 (Windows NT 5.2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36' } fromurl='http://hot.weibo.com/?v=1899&page=2' r = urllib.request.Request(url=fromurl, headers=headers) response=urllib.request.urlopen(r) page=response.read() soup= BeautifulSoup(page) tags = soup.find_all(name='div' , attrs={'class' :'WB_detail' }) for tag in tags: sender = tag.find(name='a' , attrs={'class' :'WB_name S_func1' }).get_text() text = tag.find(name='div' , attrs={'class' :'WB_text' }).get_text() thumbList = tag.find_all(name='img' , attrs={'class' :'bigcursor' }) img = [] if thumbList: for t in thumbList: img.append(t['src' ]) print (sender+text) print (img) print () print () input ()
python抓取糗百信息并入库mysql 这里抓取的页面是糗百的最近8小时糗事页面。感觉它的列表规则比较简单一些。学习pytho的urllib库基本操作与mysql的基础使用。http://dev.mysql.com/doc/connector-python/en/index.html
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 import urllib.requestimport mysql.connectorimport reurl="http://www.qiushibaike.com/8hr/page/1" response=urllib.request.urlopen(url) page=response.read() p = re.compile (r'<div class="content" title="([\d\-\s:]+)">([^<]*(?=<br\/>[^<]+)*)<\/div>(?=\s*<div class="thumb">\s*<a[^>]+>\s*(<img[^>]+\/>)\s*<\/a>\s*<\/div>)?' ) resultlist = p.findall(page.decode('utf-8' )) print (resultlist)conn = {'host' :'localhost' , 'user' :'root' , 'password' :'flake' , 'database' :'test' } conn = mysql.connector.connect(**conn) cursor = conn.cursor() insertSql = "insert into qiubai (dates, text, img) values (%s, replace(replace(%s,'\n',''),'\r',''), %s)" cursor.executemany(insertSql, resultlist) cursor.close() conn.close() input ()
python-tkinter的键盘事件监听 python-tkinter的键盘事件监听的实现,特殊字符直接打印是不会显示的,但都是正常的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 #导入tkinter from tkinter import * #定义的方法 监听键盘事件 def printkey(event): print('你按下了: ' + event.char) #实例化tk root = Tk() #实例化一个输入框 entry = Entry(root) #给输入框绑定按键监听事件<Key>为监听任何按键 <Key-x>监听其它键盘,如大写的A<Key-A>、回车<Key-Return> entry.bind('<Key>', printkey) #显示窗体 entry.pack() root.mainloop()
结果如下:
转自:https://www.zh30.com
自动化测试 selenium 模块 webdriver使用(一) 一、webdriver基本使用命令 1 from selenium import webdriver
1 2 3 4 5 6 7 >>> chrome_obj = webdriver.Chrome() >>> chrome_obj.get("https://www.baidu.com" ) >>> chrome_obj.get(r"C:\desktop\text.html" ) >>> chrome_obj.title >>> chrome_obj.current_url
二、标签导航 普通 定位标签
1 2 3 4 5 6 7 8 9 10 11 >>> label = chrome_obj.find_element_by_id("kw" )>>> label = chrome_obj.find_element_by_name("wd" )>>> label = chrome_obj.find_element_by_class_name("s_ipt" )>>> label = chrome_obj.find_element_by_tag_name("imput" ) >>> label = chrome_obj.find_element_by_link_text("a标签中的内容 准确定位" ) >>> label = chrome_obj.find_element_by_partial_link_text("a标签中的内容 模糊定位 " ) >>> label = chrome_obj.find_element_by_xpath(“放入 copy 标签中的常css路径”)>>> label = chrome_obj.find_element_by_css_selector(“input =[id ='id_name' /name='name_name' /……/]")
标签导航 xpath 标签定位复杂的情况下 考虑使用xpath
XPath即为XML路径语言,它是一种用来确定XML(标准通用标记语言的子集)文档中某部分位置的语言。XPath基于XML的树状结构,有不同类型的节点,包括元素节点,属性节点和文本节点,提供在数据结构树中找寻节点的能力。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 >>> label = chrome_obj.find_element_by_xpath("html/boday/p/input" ) >>> label = chrome_obj.find_element_by_xpath("html/boday/p/input[1]" ) >>> label = chrome_obj.find_element_by_xpath("//input" ) >>> label = chrome_obj.find_element_by_xpath("//input[2]" ) >>> label = chrome_obj.find_element_by_xpath("//form//input" ) >>> label = chrome_obj.find_element_by_xpath("//form//input[2]" ) >>> label = chrome_obj.find_element_by_xpath("//form//input/.." ) >>> label = chrome_obj.find_element_by_xpath("//form//input/." ) >>> label = chrome_obj.find_element_by_xpath("//input[@id]" ) >>> label = chrome_obj.find_element_by_xpath("//input[@id='1']" ) >>> label = chrome_obj.find_element_by_xpath("//input[@name='xiahua']" ) >>> label = chrome_obj.find_element_by_xpath("//*[countains(input)=1]" ) >>>label = chrome_obj.find_element_by_xpath("//*[countains(input)=2]" ) >>> label = chrome_obj.find_element_by _xpath("//*[local-name()='input']" ) >>> label = chrome_obj.find_element_by _xpath("//*input" ) >>> label = chrome_obj.find_element_by _xpath("//*[local-name(),'i']" ) >>> label = chrome_obj.find_element_by _xpath("//*[local-name(),'i']" ) >>> label = chrome_obj.find_element_by _xpath("//*[countains(local-name(),'i')] [last()]) # 查找当前文档中 所有包含 字母“i”的 标签 的子标签 的 最后一个元素 (有点懵逼) >>> label = chrome_obj.find_element_by _xpath(" //*[strint-length(local-name()=3 )] [last()])
三、 模拟用户操作 1 2 3 4 5 6 7 8 9 >>> label.get_attribute("type" ) >>> label.tag_name() >>> label.size>>> label.id >>> chrome_obj.maximize_window()>>> label.click() >>> label.send_keys("模拟搜索内容" )
1、模拟鼠标操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from selenium.webdriver.common.action_chains import ActionChains >>> label = chrome_obj.find_element_by_link_text("点我 悬浮 显示其他 a标签" ) >>> ActionChains(chrome_obj).move_to_element(label).perform() """ ActionChains(chrome_obj) 用于生成模拟用户行为 ; perform() 执行存储行为 """ >>> label_bel = chrome_obj.find_element_by_link_text("我是 a标签,点我页面跳转" )>>> label_bel.click() 其他鼠标操作 label.countext_lick() label.double_click() label.drag_and_drop() label.move_to_element label.click_and_hold
2、模拟键盘操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from selenium.webdriver.common.keys import Keys >>> label.send_keys("input输入的内容" ) >>> label.send_keys(Keys.BACK_SPANCE) >>>label.send_keys(Keys.CONTRL,'a' ) >>>label.send_keys(Keys.CONTRL,'v' ) >>>label.send_keys(Keys.CONTRL,'c' ) >>>label.send_keys(Keys.CONTRL,'x‘’) # 剪切 >>>label.send_keys(Keys.ENTER) # 回车
四、处理对话框 python脚本实现自动登录
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 from selenium import webdriverimport timedef automatic_login (name,pwd,url ): chrome = webdriver.Chrome() chrome.get(url) time.sleep(2 ) chrome.maximize_window() time.sleep(5 ) chrome.find_element_by_xpath("/html/body/div[3]/div[2]/div[3]/div/div" ).click() chrome.find_element_by_link_text("登录" ).click() time.sleep(5 ) name_label = chrome.find_element_by_id("id_account_l" ) name_label.clear() name_label.send_keys(name) pwd_label = chrome.find_element_by_id("id_password_l" ) pwd_label.clear() pwd_label.send_keys(pwd) time.sleep(5 ) login_label = chrome.find_element_by_id("login_btn" ) login_label.click() time.sleep(15 ) chrome.close() if __name__ == "__main__" : name = "helloyiwantong@163.com" pwd = "helloyiwantong@1234" url = "http://www.maiziedu.com/" automatic_login(name,pwd,url) python automatic login
五、控制多窗口 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 >>> frome selenium import webdrive>>> chrome = webdrive.Chrome()>>> chrome.get("https://www.baidu.come" )>>> chrome.find_element_by_id("kw" ).send_keys("红花" )>>> chrome.find_element_by_id("su" ).click() >>> chrome.find_element_by_partial_link_text("百度百科" ).click() >>> chrome.find_element_by_partial_link_text("中药" ).click() >>> chrome.window_handles ['CDwindow-D41F1F3BF5038E36E91EA7F7E7E9770D' , 'CDwindow-F2D1553323BDC39BE99DBF280804FCCC' ,'CDwindow-B41B29B8A7CB49BF191E46FF936E6A52' ,]>>> chrome.switch_to_window(chrome.window_handles[1 ]) >>> chrome.current_url()
六、模拟用户自动登录 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 from selenium import webdriverimport timefrom selenium.webdriver.support.ui import WebDriverWaitdef wait_response_time (chrome,waittime,func ): return WebDriverWait(chrome,waittime).until(func) def automatic_login (name,pwd,url ): chrome = webdriver.Chrome() chrome.get(url) time.sleep(2 ) chrome.maximize_window() chrome.find_element_by_link_text("登录" ).click() time.sleep(1 ) name_label = chrome.find_element_by_id("id_account_l" ) name_label.send_keys(" " ) name_label.clear() name_label.send_keys(name) pwd_label = chrome.find_element_by_id("id_password_l" ) pwd_label.clear() pwd_label.send_keys(pwd) time.sleep(5 ) login_label = chrome.find_element_by_id("login_btn" ) login_label.click() error_id="login-form-tips" error_message=chrome.find_element_by_id(error_id) err=error_message.text print (error_message,type (error_message)) print (err) if __name__ == "__main__" : name = "helloyiwantong@163.com" pwd = "helloyiwantong@134" url = "http://www.maiziedu.com/" automatic_login(name,pwd,url) automatic login
七、模拟用户自动登录 封装接口 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 from selenium import webdriverimport timefrom selenium.webdriver.support.ui import WebDriverWaitdef open_browse (): """ open browser obj :return: """ browse_obj = webdriver.Chrome() return browse_obj def click_url_and_clicl_loginbtn (browse,url ): """ open url and click "登录" btn :param browse: :param url: :return: """ browse.get(url) browse.maximize_window() loginbtn_lable=browse.find_element_by_link_text("登录" ) loginbtn_lable.click() time.sleep(1 ) def get_element_label (browse,element_id_dict ): """ get element lable :param browse: :param element_id_dict: :return: """ user_label = browse.find_element_by_id(element_id_dict["name" ]) pwd_label = browse.find_element_by_id(element_id_dict.get("pwd" )) login_label = browse.find_element_by_id(element_id_dict.get("login" )) return (user_label,pwd_label,login_label) def send_key_s (lable_tuple,userinfo_dict,userinfo_list ): """ send userinfo and logian :param lable_tuple: :param userinfo_dict: :param userinfo_list: :return: """ i=0 if i<=1 : for key in userinfo_list: lable_tuple[i].send_keys(userinfo_dict.get(key)) i+=1 time.sleep(1 ) lable_tuple[2 ].click() url = "http://www.maiziedu.com/" id_dict = { "name" :"id_account_l" , "pwd" : "id_password_l" , "login" :"login_btn" , } userinfo_dict={ "name" : "helloyiwantong@163.com" , "pwd" : "helloyiwantong@1234" , "url" : "http://www.maiziedu.com/" , } userinfo_list =["name" ,"pwd" ] chrome = open_browse() click_url_and_clicl_loginbtn(chrome,url) lable_tuple = get_element_label(chrome,id_dict) send_key_s(lable_tuple,userinfo_dict,userinfo_list) automatic login
更多参考: https://www.cnblogs.com/hellosecretgarden/p/9206648.html
经典参考文档:
https://blog.csdn.net/u010986776/article/details/79266448
https://blog.csdn.net/Yeoman92/article/details/83105318
QQ群:397745473